3. 分类¶
MNIST¶
[1]:
from sklearn.datasets import fetch_openml
# load data from https://www.openml.org/d/554
mnist = fetch_openml('mnist_784', version=1)
mnist
[1]:
{'data': array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
'target': array(['5', '0', '4', ..., '4', '5', '6'], dtype=object),
'frame': None,
'categories': {},
'feature_names': ['pixel1',
'pixel2',
'pixel3',
'pixel4',
'pixel5',
'pixel6',
'pixel7',
'pixel8',
'pixel9',
'pixel10',
'pixel11',
'pixel12',
'pixel13',
'pixel14',
'pixel15',
'pixel16',
'pixel17',
'pixel18',
'pixel19',
'pixel20',
'pixel21',
'pixel22',
'pixel23',
'pixel24',
'pixel25',
'pixel26',
'pixel27',
'pixel28',
'pixel29',
'pixel30',
'pixel31',
'pixel32',
'pixel33',
'pixel34',
'pixel35',
'pixel36',
'pixel37',
'pixel38',
'pixel39',
'pixel40',
'pixel41',
'pixel42',
'pixel43',
'pixel44',
'pixel45',
'pixel46',
'pixel47',
'pixel48',
'pixel49',
'pixel50',
'pixel51',
'pixel52',
'pixel53',
'pixel54',
'pixel55',
'pixel56',
'pixel57',
'pixel58',
'pixel59',
'pixel60',
'pixel61',
'pixel62',
'pixel63',
'pixel64',
'pixel65',
'pixel66',
'pixel67',
'pixel68',
'pixel69',
'pixel70',
'pixel71',
'pixel72',
'pixel73',
'pixel74',
'pixel75',
'pixel76',
'pixel77',
'pixel78',
'pixel79',
'pixel80',
'pixel81',
'pixel82',
'pixel83',
'pixel84',
'pixel85',
'pixel86',
'pixel87',
'pixel88',
'pixel89',
'pixel90',
'pixel91',
'pixel92',
'pixel93',
'pixel94',
'pixel95',
'pixel96',
'pixel97',
'pixel98',
'pixel99',
'pixel100',
'pixel101',
'pixel102',
'pixel103',
'pixel104',
'pixel105',
'pixel106',
'pixel107',
'pixel108',
'pixel109',
'pixel110',
'pixel111',
'pixel112',
'pixel113',
'pixel114',
'pixel115',
'pixel116',
'pixel117',
'pixel118',
'pixel119',
'pixel120',
'pixel121',
'pixel122',
'pixel123',
'pixel124',
'pixel125',
'pixel126',
'pixel127',
'pixel128',
'pixel129',
'pixel130',
'pixel131',
'pixel132',
'pixel133',
'pixel134',
'pixel135',
'pixel136',
'pixel137',
'pixel138',
'pixel139',
'pixel140',
'pixel141',
'pixel142',
'pixel143',
'pixel144',
'pixel145',
'pixel146',
'pixel147',
'pixel148',
'pixel149',
'pixel150',
'pixel151',
'pixel152',
'pixel153',
'pixel154',
'pixel155',
'pixel156',
'pixel157',
'pixel158',
'pixel159',
'pixel160',
'pixel161',
'pixel162',
'pixel163',
'pixel164',
'pixel165',
'pixel166',
'pixel167',
'pixel168',
'pixel169',
'pixel170',
'pixel171',
'pixel172',
'pixel173',
'pixel174',
'pixel175',
'pixel176',
'pixel177',
'pixel178',
'pixel179',
'pixel180',
'pixel181',
'pixel182',
'pixel183',
'pixel184',
'pixel185',
'pixel186',
'pixel187',
'pixel188',
'pixel189',
'pixel190',
'pixel191',
'pixel192',
'pixel193',
'pixel194',
'pixel195',
'pixel196',
'pixel197',
'pixel198',
'pixel199',
'pixel200',
'pixel201',
'pixel202',
'pixel203',
'pixel204',
'pixel205',
'pixel206',
'pixel207',
'pixel208',
'pixel209',
'pixel210',
'pixel211',
'pixel212',
'pixel213',
'pixel214',
'pixel215',
'pixel216',
'pixel217',
'pixel218',
'pixel219',
'pixel220',
'pixel221',
'pixel222',
'pixel223',
'pixel224',
'pixel225',
'pixel226',
'pixel227',
'pixel228',
'pixel229',
'pixel230',
'pixel231',
'pixel232',
'pixel233',
'pixel234',
'pixel235',
'pixel236',
'pixel237',
'pixel238',
'pixel239',
'pixel240',
'pixel241',
'pixel242',
'pixel243',
'pixel244',
'pixel245',
'pixel246',
'pixel247',
'pixel248',
'pixel249',
'pixel250',
'pixel251',
'pixel252',
'pixel253',
'pixel254',
'pixel255',
'pixel256',
'pixel257',
'pixel258',
'pixel259',
'pixel260',
'pixel261',
'pixel262',
'pixel263',
'pixel264',
'pixel265',
'pixel266',
'pixel267',
'pixel268',
'pixel269',
'pixel270',
'pixel271',
'pixel272',
'pixel273',
'pixel274',
'pixel275',
'pixel276',
'pixel277',
'pixel278',
'pixel279',
'pixel280',
'pixel281',
'pixel282',
'pixel283',
'pixel284',
'pixel285',
'pixel286',
'pixel287',
'pixel288',
'pixel289',
'pixel290',
'pixel291',
'pixel292',
'pixel293',
'pixel294',
'pixel295',
'pixel296',
'pixel297',
'pixel298',
'pixel299',
'pixel300',
'pixel301',
'pixel302',
'pixel303',
'pixel304',
'pixel305',
'pixel306',
'pixel307',
'pixel308',
'pixel309',
'pixel310',
'pixel311',
'pixel312',
'pixel313',
'pixel314',
'pixel315',
'pixel316',
'pixel317',
'pixel318',
'pixel319',
'pixel320',
'pixel321',
'pixel322',
'pixel323',
'pixel324',
'pixel325',
'pixel326',
'pixel327',
'pixel328',
'pixel329',
'pixel330',
'pixel331',
'pixel332',
'pixel333',
'pixel334',
'pixel335',
'pixel336',
'pixel337',
'pixel338',
'pixel339',
'pixel340',
'pixel341',
'pixel342',
'pixel343',
'pixel344',
'pixel345',
'pixel346',
'pixel347',
'pixel348',
'pixel349',
'pixel350',
'pixel351',
'pixel352',
'pixel353',
'pixel354',
'pixel355',
'pixel356',
'pixel357',
'pixel358',
'pixel359',
'pixel360',
'pixel361',
'pixel362',
'pixel363',
'pixel364',
'pixel365',
'pixel366',
'pixel367',
'pixel368',
'pixel369',
'pixel370',
'pixel371',
'pixel372',
'pixel373',
'pixel374',
'pixel375',
'pixel376',
'pixel377',
'pixel378',
'pixel379',
'pixel380',
'pixel381',
'pixel382',
'pixel383',
'pixel384',
'pixel385',
'pixel386',
'pixel387',
'pixel388',
'pixel389',
'pixel390',
'pixel391',
'pixel392',
'pixel393',
'pixel394',
'pixel395',
'pixel396',
'pixel397',
'pixel398',
'pixel399',
'pixel400',
'pixel401',
'pixel402',
'pixel403',
'pixel404',
'pixel405',
'pixel406',
'pixel407',
'pixel408',
'pixel409',
'pixel410',
'pixel411',
'pixel412',
'pixel413',
'pixel414',
'pixel415',
'pixel416',
'pixel417',
'pixel418',
'pixel419',
'pixel420',
'pixel421',
'pixel422',
'pixel423',
'pixel424',
'pixel425',
'pixel426',
'pixel427',
'pixel428',
'pixel429',
'pixel430',
'pixel431',
'pixel432',
'pixel433',
'pixel434',
'pixel435',
'pixel436',
'pixel437',
'pixel438',
'pixel439',
'pixel440',
'pixel441',
'pixel442',
'pixel443',
'pixel444',
'pixel445',
'pixel446',
'pixel447',
'pixel448',
'pixel449',
'pixel450',
'pixel451',
'pixel452',
'pixel453',
'pixel454',
'pixel455',
'pixel456',
'pixel457',
'pixel458',
'pixel459',
'pixel460',
'pixel461',
'pixel462',
'pixel463',
'pixel464',
'pixel465',
'pixel466',
'pixel467',
'pixel468',
'pixel469',
'pixel470',
'pixel471',
'pixel472',
'pixel473',
'pixel474',
'pixel475',
'pixel476',
'pixel477',
'pixel478',
'pixel479',
'pixel480',
'pixel481',
'pixel482',
'pixel483',
'pixel484',
'pixel485',
'pixel486',
'pixel487',
'pixel488',
'pixel489',
'pixel490',
'pixel491',
'pixel492',
'pixel493',
'pixel494',
'pixel495',
'pixel496',
'pixel497',
'pixel498',
'pixel499',
'pixel500',
'pixel501',
'pixel502',
'pixel503',
'pixel504',
'pixel505',
'pixel506',
'pixel507',
'pixel508',
'pixel509',
'pixel510',
'pixel511',
'pixel512',
'pixel513',
'pixel514',
'pixel515',
'pixel516',
'pixel517',
'pixel518',
'pixel519',
'pixel520',
'pixel521',
'pixel522',
'pixel523',
'pixel524',
'pixel525',
'pixel526',
'pixel527',
'pixel528',
'pixel529',
'pixel530',
'pixel531',
'pixel532',
'pixel533',
'pixel534',
'pixel535',
'pixel536',
'pixel537',
'pixel538',
'pixel539',
'pixel540',
'pixel541',
'pixel542',
'pixel543',
'pixel544',
'pixel545',
'pixel546',
'pixel547',
'pixel548',
'pixel549',
'pixel550',
'pixel551',
'pixel552',
'pixel553',
'pixel554',
'pixel555',
'pixel556',
'pixel557',
'pixel558',
'pixel559',
'pixel560',
'pixel561',
'pixel562',
'pixel563',
'pixel564',
'pixel565',
'pixel566',
'pixel567',
'pixel568',
'pixel569',
'pixel570',
'pixel571',
'pixel572',
'pixel573',
'pixel574',
'pixel575',
'pixel576',
'pixel577',
'pixel578',
'pixel579',
'pixel580',
'pixel581',
'pixel582',
'pixel583',
'pixel584',
'pixel585',
'pixel586',
'pixel587',
'pixel588',
'pixel589',
'pixel590',
'pixel591',
'pixel592',
'pixel593',
'pixel594',
'pixel595',
'pixel596',
'pixel597',
'pixel598',
'pixel599',
'pixel600',
'pixel601',
'pixel602',
'pixel603',
'pixel604',
'pixel605',
'pixel606',
'pixel607',
'pixel608',
'pixel609',
'pixel610',
'pixel611',
'pixel612',
'pixel613',
'pixel614',
'pixel615',
'pixel616',
'pixel617',
'pixel618',
'pixel619',
'pixel620',
'pixel621',
'pixel622',
'pixel623',
'pixel624',
'pixel625',
'pixel626',
'pixel627',
'pixel628',
'pixel629',
'pixel630',
'pixel631',
'pixel632',
'pixel633',
'pixel634',
'pixel635',
'pixel636',
'pixel637',
'pixel638',
'pixel639',
'pixel640',
'pixel641',
'pixel642',
'pixel643',
'pixel644',
'pixel645',
'pixel646',
'pixel647',
'pixel648',
'pixel649',
'pixel650',
'pixel651',
'pixel652',
'pixel653',
'pixel654',
'pixel655',
'pixel656',
'pixel657',
'pixel658',
'pixel659',
'pixel660',
'pixel661',
'pixel662',
'pixel663',
'pixel664',
'pixel665',
'pixel666',
'pixel667',
'pixel668',
'pixel669',
'pixel670',
'pixel671',
'pixel672',
'pixel673',
'pixel674',
'pixel675',
'pixel676',
'pixel677',
'pixel678',
'pixel679',
'pixel680',
'pixel681',
'pixel682',
'pixel683',
'pixel684',
'pixel685',
'pixel686',
'pixel687',
'pixel688',
'pixel689',
'pixel690',
'pixel691',
'pixel692',
'pixel693',
'pixel694',
'pixel695',
'pixel696',
'pixel697',
'pixel698',
'pixel699',
'pixel700',
'pixel701',
'pixel702',
'pixel703',
'pixel704',
'pixel705',
'pixel706',
'pixel707',
'pixel708',
'pixel709',
'pixel710',
'pixel711',
'pixel712',
'pixel713',
'pixel714',
'pixel715',
'pixel716',
'pixel717',
'pixel718',
'pixel719',
'pixel720',
'pixel721',
'pixel722',
'pixel723',
'pixel724',
'pixel725',
'pixel726',
'pixel727',
'pixel728',
'pixel729',
'pixel730',
'pixel731',
'pixel732',
'pixel733',
'pixel734',
'pixel735',
'pixel736',
'pixel737',
'pixel738',
'pixel739',
'pixel740',
'pixel741',
'pixel742',
'pixel743',
'pixel744',
'pixel745',
'pixel746',
'pixel747',
'pixel748',
'pixel749',
'pixel750',
'pixel751',
'pixel752',
'pixel753',
'pixel754',
'pixel755',
'pixel756',
'pixel757',
'pixel758',
'pixel759',
'pixel760',
'pixel761',
'pixel762',
'pixel763',
'pixel764',
'pixel765',
'pixel766',
'pixel767',
'pixel768',
'pixel769',
'pixel770',
'pixel771',
'pixel772',
'pixel773',
'pixel774',
'pixel775',
'pixel776',
'pixel777',
'pixel778',
'pixel779',
'pixel780',
'pixel781',
'pixel782',
'pixel783',
'pixel784'],
'target_names': ['class'],
'DESCR': "**Author**: Yann LeCun, Corinna Cortes, Christopher J.C. Burges \n**Source**: [MNIST Website](http://yann.lecun.com/exdb/mnist/) - Date unknown \n**Please cite**: \n\nThe MNIST database of handwritten digits with 784 features, raw data available at: http://yann.lecun.com/exdb/mnist/. It can be split in a training set of the first 60,000 examples, and a test set of 10,000 examples \n\nIt is a subset of a larger set available from NIST. The digits have been size-normalized and centered in a fixed-size image. It is a good database for people who want to try learning techniques and pattern recognition methods on real-world data while spending minimal efforts on preprocessing and formatting. The original black and white (bilevel) images from NIST were size normalized to fit in a 20x20 pixel box while preserving their aspect ratio. The resulting images contain grey levels as a result of the anti-aliasing technique used by the normalization algorithm. the images were centered in a 28x28 image by computing the center of mass of the pixels, and translating the image so as to position this point at the center of the 28x28 field. \n\nWith some classification methods (particularly template-based methods, such as SVM and K-nearest neighbors), the error rate improves when the digits are centered by bounding box rather than center of mass. If you do this kind of pre-processing, you should report it in your publications. The MNIST database was constructed from NIST's NIST originally designated SD-3 as their training set and SD-1 as their test set. However, SD-3 is much cleaner and easier to recognize than SD-1. The reason for this can be found on the fact that SD-3 was collected among Census Bureau employees, while SD-1 was collected among high-school students. Drawing sensible conclusions from learning experiments requires that the result be independent of the choice of training set and test among the complete set of samples. Therefore it was necessary to build a new database by mixing NIST's datasets. \n\nThe MNIST training set is composed of 30,000 patterns from SD-3 and 30,000 patterns from SD-1. Our test set was composed of 5,000 patterns from SD-3 and 5,000 patterns from SD-1. The 60,000 pattern training set contained examples from approximately 250 writers. We made sure that the sets of writers of the training set and test set were disjoint. SD-1 contains 58,527 digit images written by 500 different writers. In contrast to SD-3, where blocks of data from each writer appeared in sequence, the data in SD-1 is scrambled. Writer identities for SD-1 is available and we used this information to unscramble the writers. We then split SD-1 in two: characters written by the first 250 writers went into our new training set. The remaining 250 writers were placed in our test set. Thus we had two sets with nearly 30,000 examples each. The new training set was completed with enough examples from SD-3, starting at pattern # 0, to make a full set of 60,000 training patterns. Similarly, the new test set was completed with SD-3 examples starting at pattern # 35,000 to make a full set with 60,000 test patterns. Only a subset of 10,000 test images (5,000 from SD-1 and 5,000 from SD-3) is available on this site. The full 60,000 sample training set is available.\n\nDownloaded from openml.org.",
'details': {'id': '554',
'name': 'mnist_784',
'version': '1',
'format': 'ARFF',
'upload_date': '2014-09-29T03:28:38',
'licence': 'Public',
'url': 'https://www.openml.org/data/v1/download/52667/mnist_784.arff',
'file_id': '52667',
'default_target_attribute': 'class',
'tag': ['AzurePilot',
'OpenML-CC18',
'OpenML100',
'study_1',
'study_123',
'study_41',
'study_99',
'vision'],
'visibility': 'public',
'status': 'active',
'processing_date': '2018-10-03 21:23:30',
'md5_checksum': '0298d579eb1b86163de7723944c7e495'},
'url': 'https://www.openml.org/d/554'}
Scikit-Learn加载的数据集通常具有类似的字典结构,包括: - DESCR键,描述数据集 - data键,包含一个数组,每个实例为一行,每个特征为一列 - target键,包含一个带有标记的数组
[2]:
X, y = mnist['data'], mnist['target']
X.shape, y.shape
[2]:
((70000, 784), (70000,))
[3]:
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
[4]:
some_digit = X[36000]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, interpolation='nearest')
plt.axis('off')
plt.show()

[5]:
y[36000]
[5]:
'9'
事实上MNIST数据集已经分成了测试集(前60000张图像)和测试集(最后10000张图像)
[6]:
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
我们都对训练集进行数据洗牌,这样才能保证交叉验证时所有的折叠都差不多。此外,有些机器学习算法对训练实例的顺序敏感,如果连续输入许多相似的实例,可能导致执行性能不佳。
[7]:
import numpy as np
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
训练一个二元分类器¶
先简化问题,只尝试训练一个数字——9
[8]:
y_train_9 = (y_train == '9')
y_test_9 = (y_test == '9')
y_train_9 = y_train_9.astype(np.uint8)
y_test_9 = y_test_9.astype(np.uint8)
y_train_9, y_test_9
[8]:
(array([0, 0, 1, ..., 0, 0, 0], dtype=uint8),
array([0, 0, 0, ..., 0, 0, 0], dtype=uint8))
SGDClassifier分类器,能够有效处理非常大型的数据集。这部分是因为SGD独立处理训练实例,一次一个,这也使得SGD非常适合在线学习。
[9]:
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_9)
[9]:
SGDClassifier(random_state=42)
SGDClassifier在训练时是完全随机的,如果希望可以得到可复现的结果,需要设置参数random_state
[10]:
sgd_clf.predict([some_digit]), sgd_clf.predict([X_train[5]])
[10]:
(array([0], dtype=uint8), array([0], dtype=uint8))
这里面有预测错误的,也有预测成功的,下面我们计算一个预测的precision
[11]:
y_pred = sgd_clf.predict(X_test)
y_pred
[11]:
array([0, 0, 0, ..., 0, 0, 0], dtype=uint8)
[12]:
np.sum(y_pred == y_test_9)/len(y_test_9)
[12]:
0.9556
可以看到模型的预测的precision为94.06%,表面上看起来还不赖
性能考核¶
使用交叉验证测量精度¶
[13]:
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=5, random_state=42)
for train_index, test_index in skfolds.split(X_train, y_train_9):
# print(train_index, train_index.shape, test_index, test_index.shape)
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = y_train_9[train_index]
X_test_fold = X_train[test_index]
y_test_fold = y_train_9[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = np.sum(y_pred == y_test_fold)
print(n_correct/len(y_test_fold))
0.9389166666666666
0.9518333333333333
0.9514166666666667
0.9478333333333333
0.9223333333333333
也可以使用cross_val_score进行交叉验证
[14]:
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_9, cv=3, scoring="accuracy")
[14]:
array([0.93995, 0.88745, 0.94305])
从上面可以看到所有的交叉验证的准确率都达到了94%!在激动之前我们可以看看一个笨重的分类器
[15]:
from sklearn.base import BaseEstimator
class Never9Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1))
[16]:
never_9_clf = Never9Classifier()
cross_val_score(never_9_clf, X_train, y_train_9, cv=3, scoring='accuracy')
[16]:
array([0.90115, 0.8981 , 0.9033 ])
上面的分类器把所有的数字都预测为非9的,但是依然可以达到90%的准确率,这是由于偏斜数据集造成的
混淆矩阵¶
要计算混淆矩阵,需要先有一组预测才能将其与实际目标进行比较,当然可以通过测试集来进行测试,倒是现在先不要动它(测试集最好留到项目最后,准备启动分类器时在使用),作为替代,可以使用cross_val_predict()函数
[17]:
from sklearn.model_selection import cross_val_predict
y_train_predict = cross_val_predict(sgd_clf, X_train, y_train_9, cv=3)
y_train_predict, y_train_predict.shape
[17]:
(array([0, 0, 1, ..., 0, 0, 0], dtype=uint8), (60000,))
[18]:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_9, y_train_predict)
[18]:
array([[51200, 2851],
[ 1740, 4209]])
本示例中第一行表示所有“非9”(负类-Negative)的图像中:52767张被正确的分为“非9”类别(真负类-TN),1284张错误地分类成了“9”(假正类-FP);第二行表示所有的“9”(正类-Positive)的图像中:1879张被错误的分为了“非9”类别(假负类-FN),4070张被正确地分在了“9”这个类(真正类-TP)。一个完美的分类器只有真真正类和真负类,所以他的混淆矩阵只会在其对角线(左上到右下)上有非零值
[19]:
y_train_perfect_predictions = y_train_9
confusion_matrix(y_train_9, y_train_perfect_predictions)
[19]:
array([[54051, 0],
[ 0, 5949]])
精度-Precision¶
Precision尝试回答的问题:在被识别为正类别的样本中,确实为正类别的比例是多少?
做一个单独的正类预测,并确保它是正确的,就可以得到完美的精度(precision=1/1=100%)。但是这没有什么意义,因为分类器会忽略掉这个正类实例之外的所有内容。因此Accuracy通常与召回率-Recall,也称为灵敏度-Sensitivity或者真正率-TPR一起使用:
Recall尝试回答的问题:在所有正类别样本中,被正确识别为正类别的比例是多少?
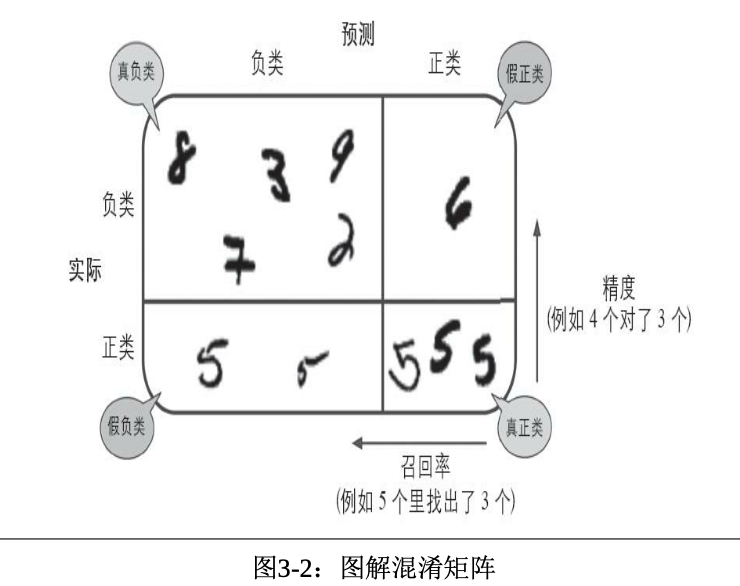
注意,Precision与Accuracy千万不要弄混了
一般来说,提高分类阈值会减少假正类-TP,从而提高Precision
提高分类阈值会导致真正类-TP的减少或不变,同时假负类-FN的值会增加或保持不变。因此召回率保持不变或下降
一般来说,如果某个模型在精确率和召回率方面均优于另一模型,则该模型可能更好。很显然,我们需要确保在精确率/召回率点处进行比较,这在实践中非常有用,因为这样做才有实际意义。例如,假设我们的垃圾邮件检测模型需要达到至少 90% 的精确率才算有用,并可以避免不必要的虚假警报。在这种情况下,将 {20% 精确率,99% 召回率} 模型与另一个 {15% 精确率,98% 召回率} 模型进行比较不是特别有意义,因为这两个模型都不符合 90% 的精确率要求。但考虑到这一点,在通过精确率和召回率比较模型时,这是一种很好的方式。
[21]:
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_9, y_train_predict)
[21]:
0.5961756373937677
[22]:
recall_score(y_train_9, y_train_predict)
[22]:
0.7075138678769541
我们可以很方便地将精度和召回率组合成一个单一的指标,称为\(F_1\)分数。\(F_1\)分数是精度和召回率的谐波平均值。正常的平均值平等对待所有的值,而谐波平均值会给予较低的值更高的权重。因此,只有当召回率和精度都很高时,分类器才能得到较高的:math:`F_1`分数。
[23]:
from sklearn.metrics import f1_score
f1_score(y_train_9, y_train_predict)
[23]:
0.6470904758244292
\(F_1\)分数对那些具有相似的精度和召回率的分类器更为有利。这不一定能一直符合你的期望:在某些情况下,你更关心的是精度,而另一些情况下,你可能真正关心的是召回率。例如,假设你训练一个分类器来检测儿童可以放心看的视频,那么你可能更青睐那种拦截了很多好视频(低召回率),但是保留下来的视频都是安全(高精度)的分类器,而不是Recall虽高,但是在产品中可能会出现一些非常糟糕的视频的分类器(这种情况下,你甚至可能会增加一个工人流水线来检查分类器选出来的视频)。反过来说,如果你训练一个分类器通过图像监控来检测小偷:你大概可以接受精度只有30%,只要召回率能达到99%(当然,安保人员会收到一些错误的警报,但是几乎所有的窃贼都在劫难逃)。
遗憾的是,鱼和熊掌不可兼得:你不能同时增加精度并减少召回率,反之亦然,这称为精度/召回率权衡。
Precision/Recall权衡¶
要理解这个权衡过程,我们来看看SGDClassifier如何进行分类决策。对于每个实例,他会给予决策函数计算出一个分值,如果该值大于阈值,则将该实例判为正类,否则便将其判为负类。Scikit-Learn不允许直接设置阈值,但是可以访问它用于预测的决策分数。不是调用分类器的predict()方法,而是调用decision_function()方法,这个方法返回每个实例的分数,然后就可以根据这些分数,使用任意阈值进行预测了
[24]:
y_scores = sgd_clf.decision_function([some_digit])
y_scores
[24]:
array([-4710.31909378])
[25]:
threshold = -5000
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
[25]:
array([ True])
如何决定使用什么阈值呢?¶
1. 首先使用cross_val_predict()函数获取训练集中所有实例的分数,但是这次需要它返回的是决策分数而不是预测结果¶
[26]:
y_scores = cross_val_predict(sgd_clf, X_train, y_train_9, cv=3, method="decision_function")
y_scores
[26]:
array([-38805.11193315, -26680.86068743, 1351.50729744, ...,
-14451.53682289, -64515.898079 , -5878.80919097])
2. 有了这些分数,可以使用precision_recall_curve()函数计算所有可能的阈值的精度和召回率:¶
[28]:
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_9, y_scores)
precisions, recalls, thresholds
[28]:
(array([0.10253184, 0.10251637, 0.10251814, ..., 1. , 1. ,
1. ]),
array([1.00000000e+00, 9.99831905e-01, 9.99831905e-01, ...,
3.36190956e-04, 1.68095478e-04, 0.00000000e+00]),
array([-63773.47532001, -63763.51347442, -63760.38332421, ...,
36057.73101653, 38985.11412538, 49742.60677835]))
[33]:
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
"""
绘制precisions, recalls vs thresholds的曲线
"""
plt.figure(figsize=(10, 6))
plt.plot(thresholds, precisions[:-1], "b--", label="Precision")
plt.plot(thresholds, recalls[:-1], "g-", label="Recall")
plt.xlabel('Threshold')
plt.legend(loc="upper left")
plt.ylim([0, 1])
[34]:
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.show()

从上图中可以看出,精度曲线比召回率曲线要崎岖一些。原因在于,当你提高阈值时,精度有时也可能会下降(尽管总体趋势是上升的)。另一方面。当阈值上升时,Recall只会下降,这就解释了为什么Recall曲线看起来很平滑。
3. 还有一种找到好的Precision/Recall权衡的方法是直接绘制Precision和Recall的函数图¶
[35]:
plt.figure(figsize=(10,9))
plt.plot(recalls[:-1], precisions[:-1])
plt.xlabel("Recalls")
plt.ylabel("Precisions")
plt.xlim([0,1])
plt.ylim([0,1])
plt.show()

由此可见,创建一个你想要的精度的分类器是相当容易的事情:只要阈值足够的高即可!然而,如果召回率太低,精度再高,其实也不怎么有用!如果有人说:“我们需要99%的精度。”你就应该问:“召回率是多少?”
ROC曲线¶
还有一种经常与二元分类器一起使用的工具,叫做受试者工作特征曲线(简称ROC)。它与Precision/Recall曲线非常相似,但是绘制的不是Precision和Recall,而是真正类率(召回率的另一名称)和假正类率(FPR)。FPR是被错误分为正类的负类实例比率。它等于1减去真负类率(TNR),后者是被正确分类为负类实例比率,也称为特异度。因此ROC曲线绘制的是灵敏度和(1-特异度)的关系。
要绘制ROC曲线,首先需要使用roc_curve()函数计算多种阈值的TPR和FPR
[36]:
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_9, y_scores)
[37]:
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0,1], 'k--')
plt.axis([0,1, 0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
[38]:
plot_roc_curve(fpr, tpr)
plt.show()

同样这里再次面临一个折中权衡:Recall(TPR)越高,分类器产生的假正类(FPR)就越多。虚线表示随机分类器的ROC曲线:一个优秀的分类器应该远离这条线越远越好
一种比较分类器的方法是测量曲线下面积(AUC)。完美的分类器的ROC AUC等于1,而纯随机分类器的ROC AUC等于0.5.
Scikit-Learn提供计算ROC AUC的函数-roc_auc_score()
[39]:
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_9, y_scores)
[39]:
0.9450408147085357
由于ROC曲线与Precision/Recall(或PR)曲线非常相似,因此你可能会问如何决定使用哪种曲线。有一个经验法则,当正类非常少见或者你更关注假正类而不是假负类时,你应该选择PR曲线,反之是ROC曲线。例如,看前面的ROC曲线图,你可能会觉得分类器真不错。但这主要是因为负类(非9)相比,正类(数字9)的数量真的很少。相比之下,PR曲线可以清楚的说明分类器还有改进的空间(曲线还可以更接近右上角)。
实际上,如果您有一个 AUC 为 1.0 的“完美”分类器,您应该感到可疑,因为这可能表明您的模型中存在错误。例如,您的训练数据可能过拟合,或者带标签数据可能被复制到其中一项特征中。
AUC 以相对预测为依据,因此保持相对排名的任何预测变化都不会对 AUC 产生影响。而对其他指标而言显然并非如此,例如平方误差、对数损失函数或预测偏差(稍后讨论)。
训练一个RandomForestClassifier分类器,并比较它和SGDClassifier分类器的ROC曲线和ROC AUC分数。RandomForestClassifier类没有decision_function()方法,但是它有dict_proba()方法。Scikit-Learn的分类器通常都会有这两种方法中的一种。``dict_proba()``方法返回一个数组,其中每一行为一个实例,每列代表一个类别,意思是给定实例属于给定类别的概率
[40]:
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_9, cv=3, method='predict_proba')
y_probas_forest
[40]:
array([[0.98, 0.02],
[1. , 0. ],
[0.49, 0.51],
...,
[1. , 0. ],
[0.91, 0.09],
[0.96, 0.04]])
要绘制ROC曲线,需要的是分数值而不是概率大小。一种简单的解决方案是:直接使用正类的概率值作为分数值:
[41]:
y_scores_forest = y_probas_forest[:, 1]
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_9, y_scores_forest)
fpr_forest, tpr_forest, thresholds_forest
[41]:
(array([0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 1.85010453e-05,
1.85010453e-05, 3.70020906e-05, 3.70020906e-05, 3.70020906e-05,
3.70020906e-05, 3.70020906e-05, 3.70020906e-05, 3.70020906e-05,
5.55031359e-05, 7.40041812e-05, 9.25052265e-05, 9.25052265e-05,
9.25052265e-05, 9.25052265e-05, 9.25052265e-05, 1.48008362e-04,
1.48008362e-04, 1.48008362e-04, 1.48008362e-04, 1.48008362e-04,
1.85010453e-04, 1.85010453e-04, 2.22012544e-04, 2.40513589e-04,
2.77515680e-04, 3.14517770e-04, 3.33018816e-04, 3.51519861e-04,
4.81027178e-04, 5.55031359e-04, 5.92033450e-04, 7.21540767e-04,
7.77043903e-04, 8.51048084e-04, 9.80555401e-04, 1.09156167e-03,
1.31357422e-03, 1.44308153e-03, 1.59108990e-03, 1.85010453e-03,
2.12762021e-03, 2.34963275e-03, 2.49764112e-03, 2.79365784e-03,
3.03417143e-03, 3.36719025e-03, 3.75571220e-03, 4.14423415e-03,
4.55125715e-03, 4.79177074e-03, 5.18029269e-03, 5.64281882e-03,
6.10534495e-03, 6.71587945e-03, 7.27091081e-03, 8.01095262e-03,
8.80649757e-03, 9.45403415e-03, 1.04160885e-02, 1.13781429e-02,
1.23957004e-02, 1.33947568e-02, 1.43938133e-02, 1.58923979e-02,
1.71319680e-02, 1.87970620e-02, 2.05731624e-02, 2.23862648e-02,
2.50319143e-02, 2.77885701e-02, 3.07857394e-02, 3.41529296e-02,
3.84266711e-02, 4.25524042e-02, 4.76216906e-02, 5.37085345e-02,
6.05354203e-02, 6.79913415e-02, 7.73898725e-02, 8.73064328e-02,
9.97576363e-02, 1.15132005e-01, 1.34243585e-01, 1.58609461e-01,
1.89321197e-01, 2.30652532e-01, 2.92945551e-01, 3.88096427e-01,
5.60415163e-01, 1.00000000e+00]),
array([0. , 0.01344764, 0.03748529, 0.06488485, 0.09951252,
0.12892923, 0.15952261, 0.18893932, 0.22070936, 0.25348798,
0.28307279, 0.31551521, 0.3419062 , 0.36678433, 0.39065389,
0.41183392, 0.43469491, 0.45503446, 0.47638259, 0.49386452,
0.51151454, 0.53118171, 0.54815935, 0.56614557, 0.58245083,
0.59808371, 0.61304421, 0.62649185, 0.63859472, 0.65288284,
0.66464952, 0.67574382, 0.68683812, 0.6987729 , 0.70936292,
0.71877626, 0.72768533, 0.73777105, 0.74684821, 0.7545806 ,
0.76399395, 0.77407968, 0.78618255, 0.79307447, 0.80080686,
0.80937973, 0.81543116, 0.82349975, 0.83005547, 0.83543453,
0.84199025, 0.8475374 , 0.85241217, 0.85829551, 0.86535552,
0.86905362, 0.87493696, 0.87981173, 0.88418222, 0.88905698,
0.89309128, 0.89847033, 0.9033451 , 0.9072113 , 0.91259035,
0.91612036, 0.91880988, 0.92284418, 0.92637418, 0.93124895,
0.93494705, 0.93746848, 0.94099849, 0.94335182, 0.94503278,
0.94755421, 0.95057993, 0.95343755, 0.95814423, 0.96150614,
0.96352328, 0.9663809 , 0.96923853, 0.97125567, 0.97360901,
0.97495377, 0.97680282, 0.97865187, 0.9815095 , 0.98335855,
0.98487141, 0.98688855, 0.9889057 , 0.99075475, 0.99327618,
0.99495714, 0.9963019 , 0.99731047, 0.99865524, 0.99949571,
0.99966381, 1. ]),
array([2. , 1. , 0.99, 0.98, 0.97, 0.96, 0.95, 0.94, 0.93, 0.92, 0.91,
0.9 , 0.89, 0.88, 0.87, 0.86, 0.85, 0.84, 0.83, 0.82, 0.81, 0.8 ,
0.79, 0.78, 0.77, 0.76, 0.75, 0.74, 0.73, 0.72, 0.71, 0.7 , 0.69,
0.68, 0.67, 0.66, 0.65, 0.64, 0.63, 0.62, 0.61, 0.6 , 0.59, 0.58,
0.57, 0.56, 0.55, 0.54, 0.53, 0.52, 0.51, 0.5 , 0.49, 0.48, 0.47,
0.46, 0.45, 0.44, 0.43, 0.42, 0.41, 0.4 , 0.39, 0.38, 0.37, 0.36,
0.35, 0.34, 0.33, 0.32, 0.31, 0.3 , 0.29, 0.28, 0.27, 0.26, 0.25,
0.24, 0.23, 0.22, 0.21, 0.2 , 0.19, 0.18, 0.17, 0.16, 0.15, 0.14,
0.13, 0.12, 0.11, 0.1 , 0.09, 0.08, 0.07, 0.06, 0.05, 0.04, 0.03,
0.02, 0.01, 0. ]))
[45]:
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, 'b:', label='SGD')
plt.plot(fpr_forest, tpr_forest, label="Random Forest")
plt.xlabel("False Positive Rate")
plt.ylabel('True Postitive Rate')
plt.legend(loc='lower right')
plt.show()

从图中可以看出RandomForestClassifier的ROC曲线比SGDClassifier好的多:它离左上角更接近。因此它的ROC AUC的分数也高的多
[46]:
roc_auc_score(y_train_9, y_scores_forest)
[46]:
0.9955051727526318
再测一下precision与recall的得分
[47]:
y_train_forest_predict = cross_val_predict(forest_clf, X_train, y_train_9, cv=3)
y_train_forest_predict
[47]:
array([0, 0, 1, ..., 0, 0, 0], dtype=uint8)
[48]:
precision_score(y_train_9, y_train_forest_predict)
[48]:
0.9831207065750736
[49]:
recall_score(y_train_9, y_train_forest_predict)
[49]:
0.8419902504622626
可以看到RandomForestClasssifier拥有98.31%的Precision和84.20%的ReCall,也还不错。由于正类9的数量很少,我们应该关注PR曲线,下面把RandomForestClassifier的PR曲线与SGDClassifier的PR曲线绘制在一起看看
[50]:
precisions_forest, recalls_forest, thresholds_forest = precision_recall_curve(y_train_9, y_scores_forest)
precisions_forest, recalls_forest, thresholds_forest
[50]:
(array([0.09915 , 0.1641095 , 0.22085206, 0.27283582, 0.32244565,
0.3667698 , 0.40843224, 0.44884163, 0.48642403, 0.52177384,
0.55439093, 0.58344951, 0.61417323, 0.64087367, 0.66727794,
0.69302326, 0.71604938, 0.73605287, 0.75786988, 0.77604307,
0.79285616, 0.80903317, 0.82539683, 0.83675866, 0.84808612,
0.8592919 , 0.86776478, 0.8784375 , 0.88573232, 0.89310785,
0.90067829, 0.90808163, 0.91555115, 0.9204944 , 0.92689515,
0.93292371, 0.93755376, 0.94269839, 0.94651 , 0.95047754,
0.95378301, 0.95574744, 0.95936876, 0.96284093, 0.96639586,
0.96945427, 0.97162188, 0.97444634, 0.97573094, 0.97782491,
0.98055231, 0.98312071, 0.98454834, 0.98582551, 0.98810004,
0.9891925 , 0.99053693, 0.99126092, 0.99180156, 0.9932045 ,
0.99352751, 0.99431197, 0.99578527, 0.99596503, 0.99614163,
0.99654696, 0.99696899, 0.99716446, 0.99760019, 0.99755859,
0.9980139 , 0.99798082, 0.9979445 , 0.99789861, 0.9978581 ,
0.99863089, 0.99859669, 0.99855908, 0.99851764, 0.99846908,
0.99873578, 0.9990151 , 0.99931973, 0.99929478, 0.99926172,
0.9992272 , 0.99918434, 0.99914015, 0.99908425, 0.9995086 ,
0.99946752, 1. , 1. , 1. , 1. ,
1. , 1. , 1. , 1. , 1. ,
1. , 1. ]),
array([1. , 0.99966381, 0.99949571, 0.99865524, 0.99731047,
0.9963019 , 0.99495714, 0.99327618, 0.99075475, 0.9889057 ,
0.98688855, 0.98487141, 0.98335855, 0.9815095 , 0.97865187,
0.97680282, 0.97495377, 0.97360901, 0.97125567, 0.96923853,
0.9663809 , 0.96352328, 0.96150614, 0.95814423, 0.95343755,
0.95057993, 0.94755421, 0.94503278, 0.94335182, 0.94099849,
0.93746848, 0.93494705, 0.93124895, 0.92637418, 0.92284418,
0.91880988, 0.91612036, 0.91259035, 0.9072113 , 0.9033451 ,
0.89847033, 0.89309128, 0.88905698, 0.88418222, 0.87981173,
0.87493696, 0.86905362, 0.86535552, 0.85829551, 0.85241217,
0.8475374 , 0.84199025, 0.83543453, 0.83005547, 0.82349975,
0.81543116, 0.80937973, 0.80080686, 0.79307447, 0.78618255,
0.77407968, 0.76399395, 0.7545806 , 0.74684821, 0.73777105,
0.72768533, 0.71877626, 0.70936292, 0.6987729 , 0.68683812,
0.67574382, 0.66464952, 0.65288284, 0.63859472, 0.62649185,
0.61304421, 0.59808371, 0.58245083, 0.56614557, 0.54815935,
0.53118171, 0.51151454, 0.49386452, 0.47638259, 0.45503446,
0.43469491, 0.41183392, 0.39065389, 0.36678433, 0.3419062 ,
0.31551521, 0.28307279, 0.25348798, 0.22070936, 0.18893932,
0.15952261, 0.12892923, 0.09951252, 0.06488485, 0.03748529,
0.01344764, 0. ]),
array([0. , 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.1 ,
0.11, 0.12, 0.13, 0.14, 0.15, 0.16, 0.17, 0.18, 0.19, 0.2 , 0.21,
0.22, 0.23, 0.24, 0.25, 0.26, 0.27, 0.28, 0.29, 0.3 , 0.31, 0.32,
0.33, 0.34, 0.35, 0.36, 0.37, 0.38, 0.39, 0.4 , 0.41, 0.42, 0.43,
0.44, 0.45, 0.46, 0.47, 0.48, 0.49, 0.5 , 0.51, 0.52, 0.53, 0.54,
0.55, 0.56, 0.57, 0.58, 0.59, 0.6 , 0.61, 0.62, 0.63, 0.64, 0.65,
0.66, 0.67, 0.68, 0.69, 0.7 , 0.71, 0.72, 0.73, 0.74, 0.75, 0.76,
0.77, 0.78, 0.79, 0.8 , 0.81, 0.82, 0.83, 0.84, 0.85, 0.86, 0.87,
0.88, 0.89, 0.9 , 0.91, 0.92, 0.93, 0.94, 0.95, 0.96, 0.97, 0.98,
0.99, 1. ]))
[56]:
plt.figure(figsize=(10, 6))
plt.plot(recalls_forest[:-1], precisions_forest[:-1], 'r:', label='Random Forest')
plt.plot(recalls[:-1], precisions[:-1], label='SGD')
plt.legend(loc='lower left')
plt.axis([0,1,0,1])
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.show()

多元分类器¶
OvA策略¶
也称为one-versus-the-rest,例如,要创建一个系统将数字图像分为10类(从0到9),一种训练方法是训练10个二元分类器,每个数字一个(0-检测器, 1-检测器, 2-检测器,等等,以此类推)。然后,当你需要对一张图像检测分类时。获取每个分类器的决策分数,那个分类器给分最高,就将其分为那个类。
OvO策略¶
为每一个数字训练一个二元分类器:一个用于区分0和1,一个区分0和2,一个区分1和2,以此类推。如果存在N个类别,那么需要训练\(N \times (N-1) \div 2\)个分类器。对于MNIST问题,这意味着训练45个二元分类器!当需要对一张图片进行分类时,需要运行45个分类器对图片进行分类,最后看那个类别获胜的多。OvO的主要优点在于,每个分类器只需要用到部分训练集对其必须区分的两个类别进行训练。
有些算法(例如SVM分类器)在数据规模扩大是表现很糟糕,因此对于这类算法,OvO是一个优先的选择,由于在较小训练集上分别训练多个分类器比在大型数据集上训练少数分类器要快的多。但是对于大多数二元分类器来说,OvA策略还是更好的选择。
Scikit-Learn可以检测到你尝试使用二元分类算法进行多类别分类任务,它会自动运行OvA(SVM分类器除外,它会使用OvO)。
[57]:
sgd_clf.fit(X_train, y_train)
sgd_clf.predict([some_digit])
[57]:
array(['4'], dtype='<U1')
上面的代码看起来非常简单,而在内部,Scikit-Learn实际上训练了10个二元分类器,获得它们对图片的决策分数,然后选择了分数最高的类别
[58]:
some_digit_scores = sgd_clf.decision_function([some_digit])
some_digit_scores
[58]:
array([[-70447.43100346, -18603.88903056, -25498.35295109,
-2148.1008376 , -1640.21582961, -2561.97569916,
-44614.56772366, -10441.93373236, -5217.19704943,
-2298.91455784]])
[59]:
np.argmax(some_digit_scores)
[59]:
4
[60]:
sgd_clf.classes_
[60]:
array(['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], dtype='<U1')
[61]:
sgd_clf.classes_[4]
[61]:
'4'
当训练分类器时,目标类别的列表会储存在classes_这个属性中,按值的大小排列
[ ]:
如果想要强制Scikit-Learn使用一对一或者一对多的策略,可以使用OneVsOneClassifier或OneVsRestClassifier类
[62]:
from sklearn.multiclass import OneVsOneClassifier
ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42))
ovo_clf.fit(X_train, y_train)
ovo_clf.predict([some_digit])
[62]:
array(['9'], dtype=object)
[63]:
len(ovo_clf.estimators_)
[63]:
45
[64]:
forest_clf.fit(X_train, y_train)
forest_clf.predict([some_digit])
[64]:
array(['9'], dtype=object)
这次Scikit-Learn不必运行OvA或者OvO了,因为Random Forest直接可以将实例分为多个类别。
[65]:
forest_clf.predict_proba([some_digit])
[65]:
array([[0. , 0. , 0. , 0. , 0.06, 0.02, 0. , 0.02, 0.01, 0.89]])
要评估这些分类器,使用交叉验证,我们可以使用cross_val_score()函数评估一下SGDClassifier的准确率
[66]:
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring='accuracy')
[66]:
array([0.88005, 0.8818 , 0.86965])
所有的测试折叠上都超过了86%,如果是一个随机分类器,准确率大概是10%,所以这个结果不是太糟,但是依然有提升的空间。例如,将输入进行简单的缩放,可以将准确率提升到90%以上
[67]:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring='accuracy')
[67]:
array([0.89575, 0.89875, 0.90535])
错误分析¶
在这里,假设你已经找到了一个潜力的模型,现在你希望找到一些方法对其进一步改进,方法之一就是分析其错误类型。
首先,看看混淆矩阵¶
[68]:
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx
[68]:
array([[5592, 0, 14, 9, 9, 44, 27, 4, 223, 1],
[ 1, 6413, 43, 19, 3, 45, 5, 7, 196, 10],
[ 26, 28, 5237, 87, 72, 25, 64, 40, 368, 11],
[ 26, 23, 117, 5217, 0, 208, 24, 41, 407, 68],
[ 11, 14, 45, 11, 5247, 9, 31, 16, 310, 148],
[ 30, 17, 25, 163, 52, 4467, 80, 16, 504, 67],
[ 28, 17, 51, 1, 39, 89, 5547, 4, 142, 0],
[ 17, 12, 55, 23, 46, 12, 5, 5714, 174, 207],
[ 17, 69, 35, 91, 3, 125, 31, 6, 5430, 44],
[ 21, 23, 32, 60, 117, 34, 1, 169, 359, 5133]])
[69]:
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()

将混淆矩阵中的每个值除以相应类别中的图片的数量,这样比较的是错误率而不是错误的绝对值:
[70]:
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx/row_sums
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()

每行代表实际类别,而每列表示预测类别。第8列和第9列整体看起来很亮,说明有许多图片被错误地分类为数字8或数字9了。同样类别8和类别9的行看起来很亮,说明数字8和数字9经常会跟其他数字混淆。相反一些行很暗,比如行1,这意味着大多数数字1都被正确地分类(有一些与数字8弄混了而已,但仅此而已)。注意。错误不是完全对称的,比如,数字5被错分为数字8的数量比数字8被错分为数字5的数量要多。
分析混淆矩阵通常可以帮助你深入了解如何改进分类器。通过上图,你的精力可以花在改进数字8和数字9的分类,以及修正数字3和数字5的混淆上。例如,可以试着收集更多这些数字的训练数据。或者,也可以开发一些新特征来改进分类器——例如可以写一个算法来计算闭环的数量,在或者,还可以对图片进行预处理(例如,使用Scikit-Image, Pillow或OpenCV)让某些模式更为突出,比如闭环之类。
分析单个错误也可以为分类器提供洞察:它在做什么?它为什么失败?但这通常更加困难和耗时。例如,我们来看看数字3和数字5的例子:
[74]:
def plot_digits(instances, images_per_row=10, **options):
size = 28
images_per_row = min(len(instances), images_per_row)
images = [instance.reshape(size,size) for instance in instances]
n_rows = (len(instances) - 1) // images_per_row + 1
row_images = []
n_empty = n_rows * images_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row * images_per_row : (row + 1) * images_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap = matplotlib.cm.binary, **options)
plt.axis("off")
[76]:
cl_a, cl_b = '3', '5'
X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)]
X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)]
X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)]
X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)]
plt.figure(figsize=(8, 8))
plt.subplot(221); plot_digits(X_aa[:25], images_per_row=5)
plt.subplot(222); plot_digits(X_ab[:25], images_per_row=5)
plt.subplot(223); plot_digits(X_ba[:25], images_per_row=5)
plt.subplot(224); plot_digits(X_bb[:25], images_per_row=5)

分类器在左下方和右上方的矩阵里弄错了数字,原因在于,我们使用的简单的SGDClassifier模型是一个线性模型。它所做的就是为每一个像素分配一个各个类别的权重,当他看到新的图像时,将加权后的像素强度汇总,从而得到一个分数进行分类。而数字3和数字5只在一部分像素上有区别,所以分类器很容易将其弄混。
数字3和数字5之间的主要区别是在于连接顶线和下方弧线的中间那段小线条的位置。如果您写的数字3将连接点略往左移,分类器就可能将其分类为数字5,反之亦然。换言之,这个分类器对图像位移和旋转非常敏感。因此,减少数字3和数字5混淆的方法之一,就是对图片进行预处理,确保他们位于中心位置并且没有旋转。这同样有助于减少其他的错误。
多标签分类¶
分类器为每个实例产出多个类别
[78]:
from sklearn.neighbors import KNeighborsClassifier
y_train_num = y_train.astype(np.uint8)
y_train_large = (y_train_num >= 7)
y_train_large
[78]:
array([False, False, True, ..., False, False, False])
[79]:
y_train_odd = (y_train_num % 2 == 1)
y_train_odd
[79]:
array([False, False, True, ..., True, False, False])
[80]:
y_multilabel = np.c_[y_train_large, y_train_odd]
y_multilabel
[80]:
array([[False, False],
[False, False],
[ True, True],
...,
[False, True],
[False, False],
[False, False]])
[81]:
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
[81]:
KNeighborsClassifier()
[82]:
knn_clf.predict([some_digit])
[82]:
array([[ True, True]])
评估多标签分类器的方法很多,如何选择正确的度量指标取决于你的项目。比如方法之一是测量每个标签的\(F_1\)分数,然后简单的平均。
[83]:
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_train, cv=3)
f1_score(y_train,y_train_knn_pred, average='macro')
[83]:
0.9677291043813279
这里假设所有的标签同等重要,但实际上是不可能的。特别是,如果训练的照片里爱丽丝比鲍勃和查理都要多得多,你可能想给区分爱丽丝的分类器更高的权重。一个简单的方法是给每个标签设置一个等于其自身支持的权重(也就是具有该目标标签的示例的数量)。只需要在上面的代码中设置average="weighted"即可
多输出分类¶
多输出-多类别分类是多标签的泛化,其标签也可以是多种类别的(比如它可以有两个以上可能的值)。
为了说明这个问题,构建一个系统去除图片中的噪声。给它输入一张有噪声的图像,他将输出一张干净的图像,跟其他的MNIST图像一样,以像素强度的一个数组做出呈现方式。请注意,这个分类器的输出是多个标签(一个像素点一个标签),每个标签可以有多个值(像素强度范围为0到255)。所以这是个多输出分类系统的例子
PS:分类和回归之前的界限有时很模糊,比如这个例子。可以说,预测像素强度更像是一个回归任务而不是分类任务。而多输出系统也不仅仅限于分类任务,可以让一个系统给每个实例输出多个标签,同时包括类别标签和值标签。
[86]:
# 创建训练集和测试集
noise_train = np.random.randint(0, 100, (len(X_train), 784))
noise_test = np.random.randint(0, 100, (len(X_test), 784))
X_train_mod = X_train + noise_train
X_test_mod = X_test + noise_test
y_train_mod = X_train
y_test_mod = X_test
[92]:
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[15]])
[98]:
plt.figure(figsize=(8,8))
plt.subplot(221); plot_digits([X_test_mod[15]])
plt.subplot(222); plot_digits(clean_digit)

[ ]: