7.6 堆叠法(Stacking)¶
堆叠法,又称为层叠泛化法。基于一个简单的想法:与其使用一些简单的函数(比如硬投票)来聚合集成中所有预测器的预测,我们为什么不训练一个模型来执行这个聚合呢?图7-12显示了在新实例上执行回归任务的这样一个集成。底部的三个预测器分别预测了不同的值(3.1、2.7和2.9),然后最终的预测器(称为混合器或元学习器)将这些预测作为输入,进行最终预测(3.0).
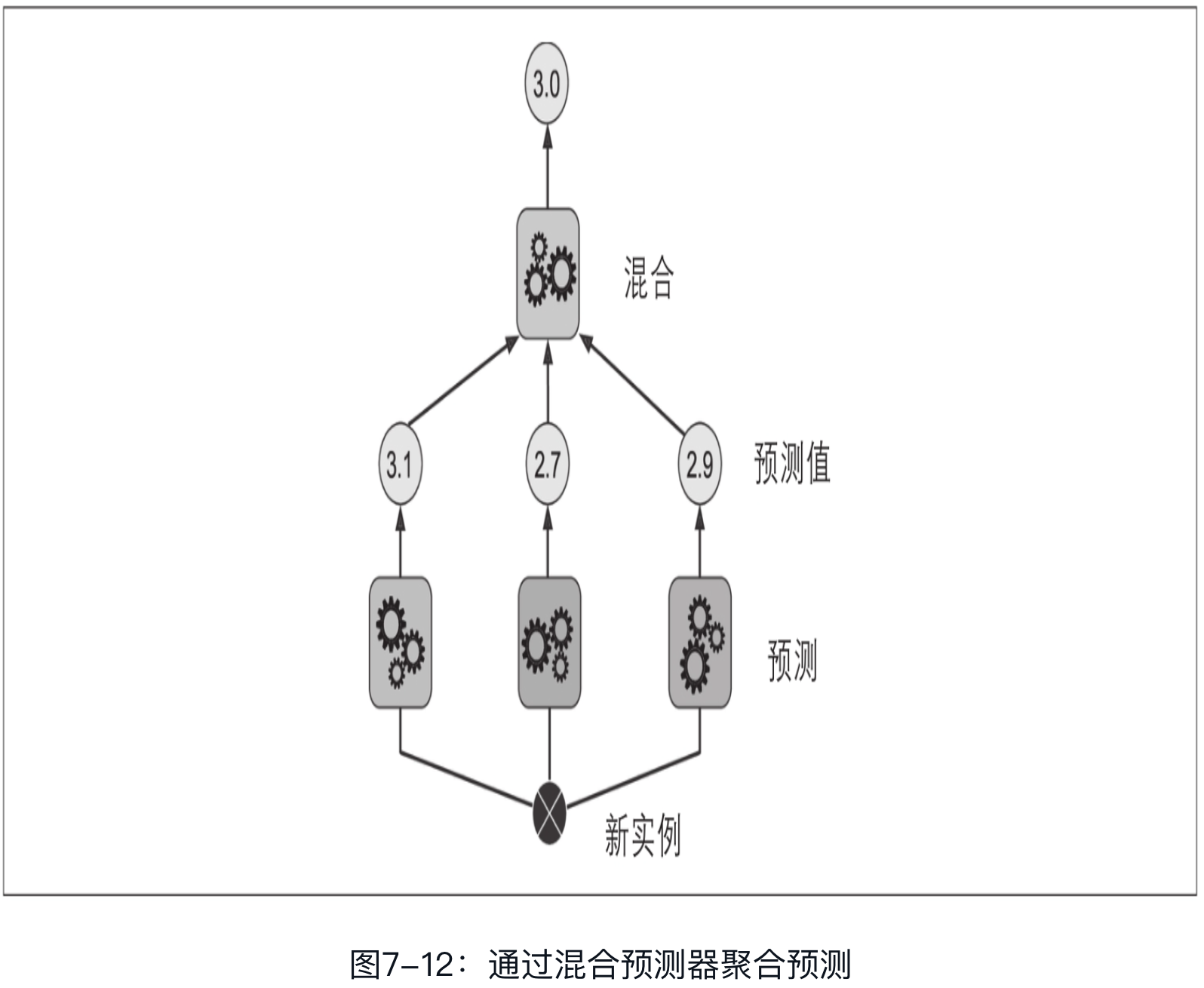
训练混合器的常用方法是使用留存集.
也可以使用折外(out-of-fold)预测。在某些情况下,这才被称为堆叠(stacking),而使用留存集被称为混合(blending)。但是对多数人而言,这二者是同义词。
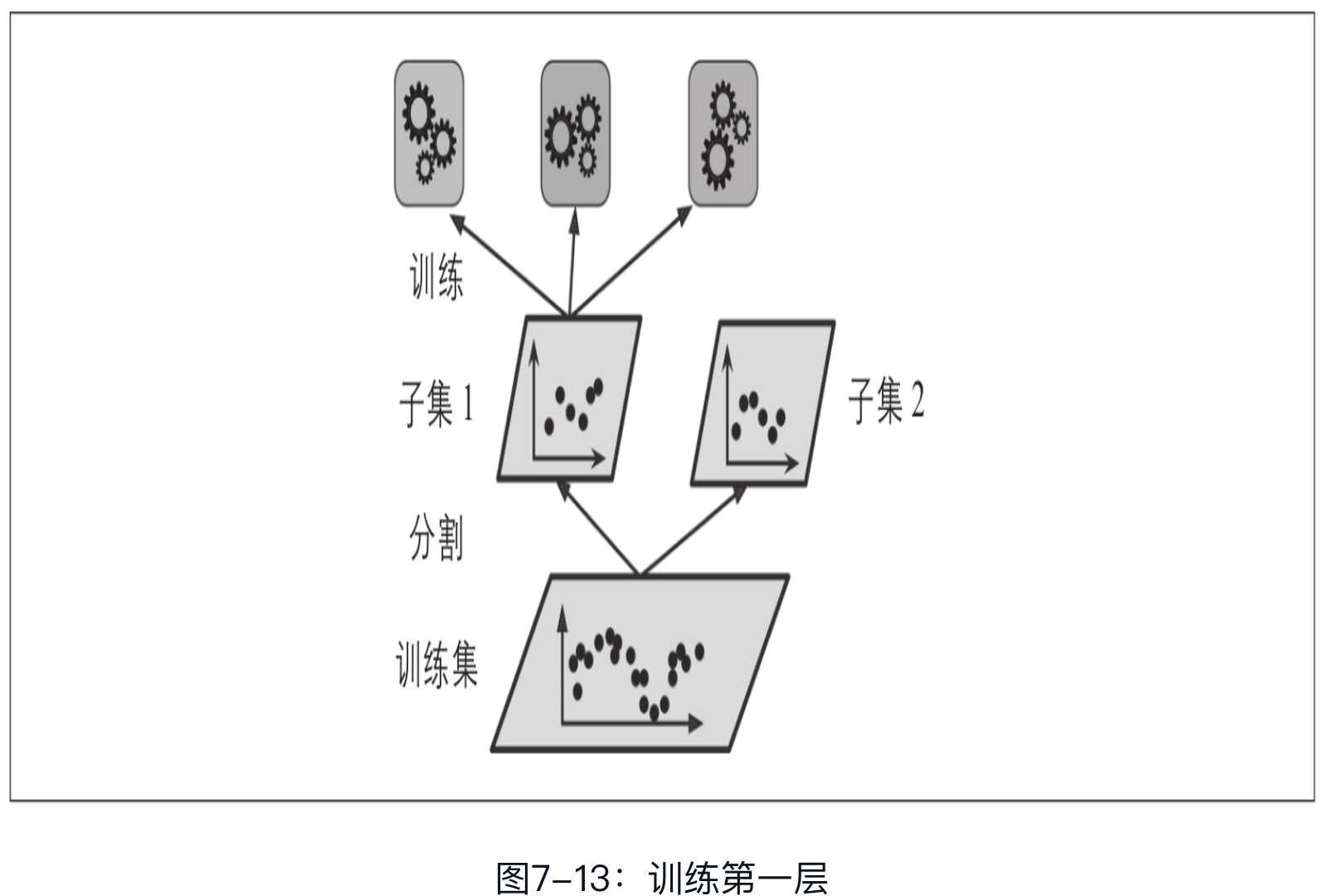
首先,将训练集分为两个子集,第一个子集用来训练第一层的预测器(见图7-13)
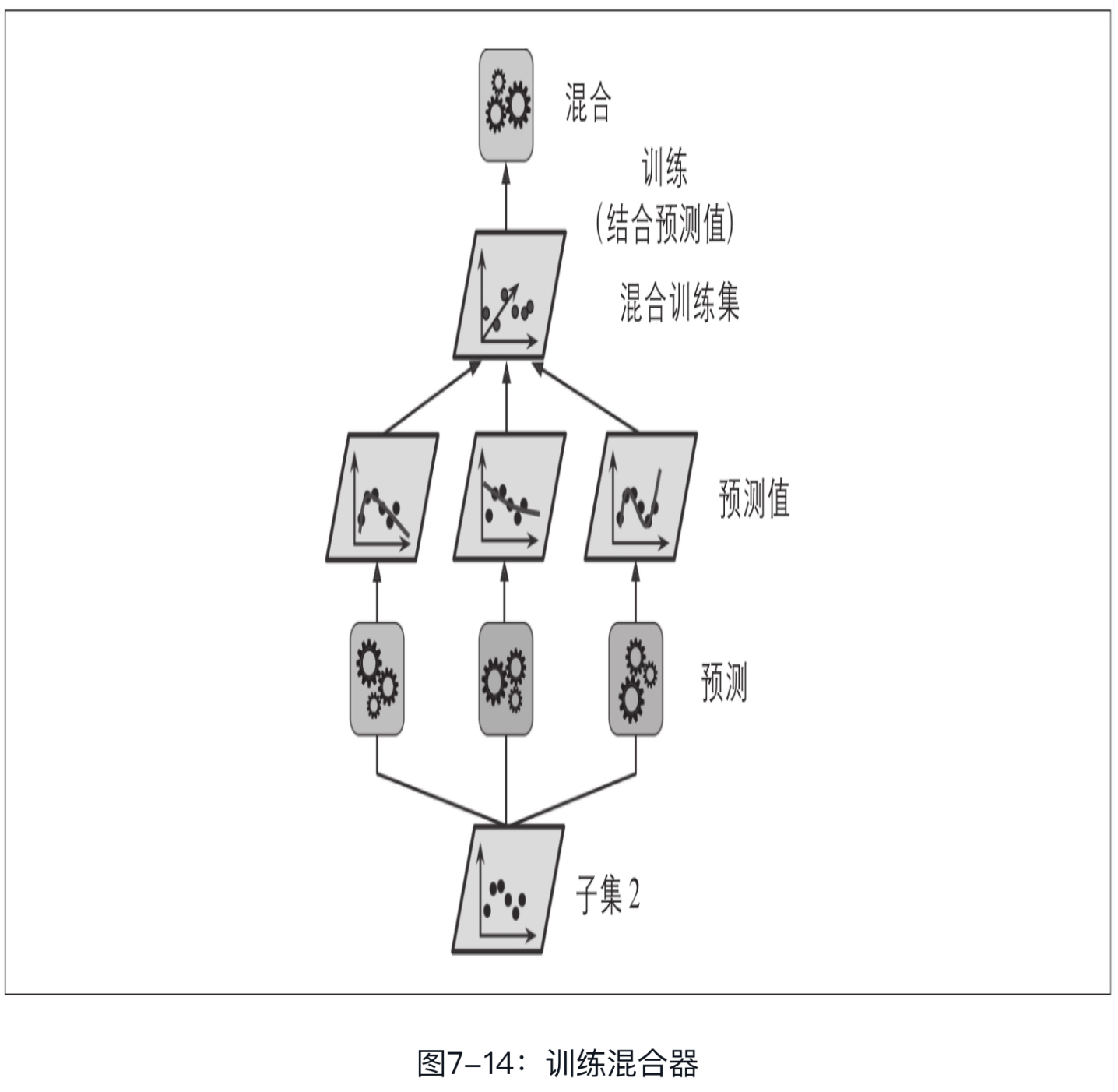
然后,用第一层的预测器在第二个(留存)子集上进行预测(见图7-14)。因为预测器在训练时从未见过这些实例,所以可以确保预测是“干净的”。那么现在对于留存集中的每个实例都有了三个预测值。我们可以使用这些预测值作为输入特征,创建一个新的训练集(新的训练集有三个维度),并保留目标值。在这个新的训练集上训练混合器,让它学习根据第一层的预测来预测目标值。
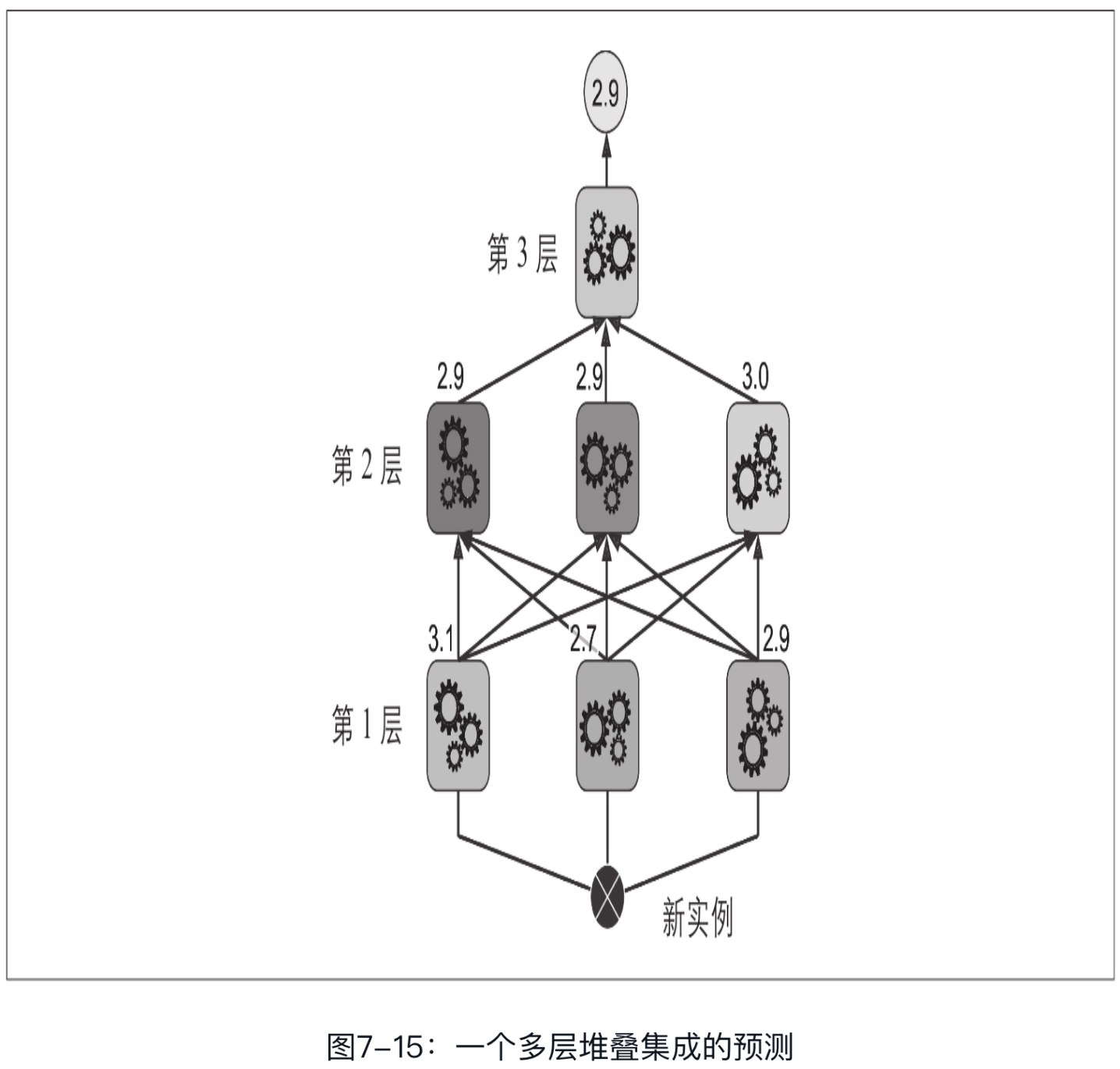
事实上,通过这种方法可以训练多种不同的混合器(例如,一个使用线性回归,另一个使用随机森林回归,等等)。于是我们可以得到一个混合器层。诀窍在于将训练集分为三个子集:第一个用来训练第一层,第二个用来创造训练第二层的新训练集(使用第一层的预测),而第三个用来创造训练第三层的新训练集(使用第二层的预测)。一旦训练完成,我们可以按照顺序遍历每层来对新实例进行预测,如图7-15所示。
不幸的是,Scikit-Learn不直接支持堆叠,但是推出自己的实现并不太难, 也可是使用开源方案比如DESlib.